The Promise and Peril of Data Contracts

The data industry is maturing in it's approach to data mesh architectures and the rise of data contracts. Data mesh promises domain-driven decentralization, each domain team treats data as a product to serve others, with autonomy and agility. Data contracts, on the surface, seem like a perfect complement: they formalize agreements between data producers and consumers, aiming to prevent broken pipelines and ensure trust. But are they truly the boon they appear to be? This white paper critically examines the value of data contracts within a data mesh context. I argue that while data contracts offer benefits like trust, stability, and quality enforcement, they may also impose rigidity that stifles innovation and slows time-to-market for data consumers. Drawing parallels to traditional software interface contracts, we explore whether strict data contracts risk repeating past mistakes in a system designed for domain autonomy and speed. We present the pros and cons, cite expert opinions, and consider how to balance governance with agility in the spirit of data mesh.
Data Mesh and Data Products: Embracing Domain Autonomy
Data mesh is a decentralized data architecture paradigm that breaks away from monolithic architectures such as data lakes and data warehouses. Conceived by Zhamak Dehghani in 2019, it rests on four key principles: domain-oriented ownership, data as a product, self-serve data infrastructure, and federated governance. In a data mesh, each domain (business area) owns its data and provides it to others as a product, complete with documentation and quality assurances. The goal is to empower domain teams to move fast and innovate, while increasing quality, and ensuring data is discoverable, reliable, and usable across the organization. As Dehghani puts it, data mesh is a shift to 'recognizing data as a product' rather than a byproduct.
A data product in this context is a curated dataset or data service that a domain team offers to the rest of the enterprise. It comes with metadata, quality metrics, and interfaces for consumption. Crucially, data products are meant to be consumer-centric, designed with the consumers' needs in mind, and to evolve as those needs change. The broader goals of data mesh and data product thinking emphasize decentralization, domain ownership, and agility. Each domain should be autonomous to adapt its data product quickly without heavy central coordination, fostering innovation and faster time-to-market for new use cases and capabilities.
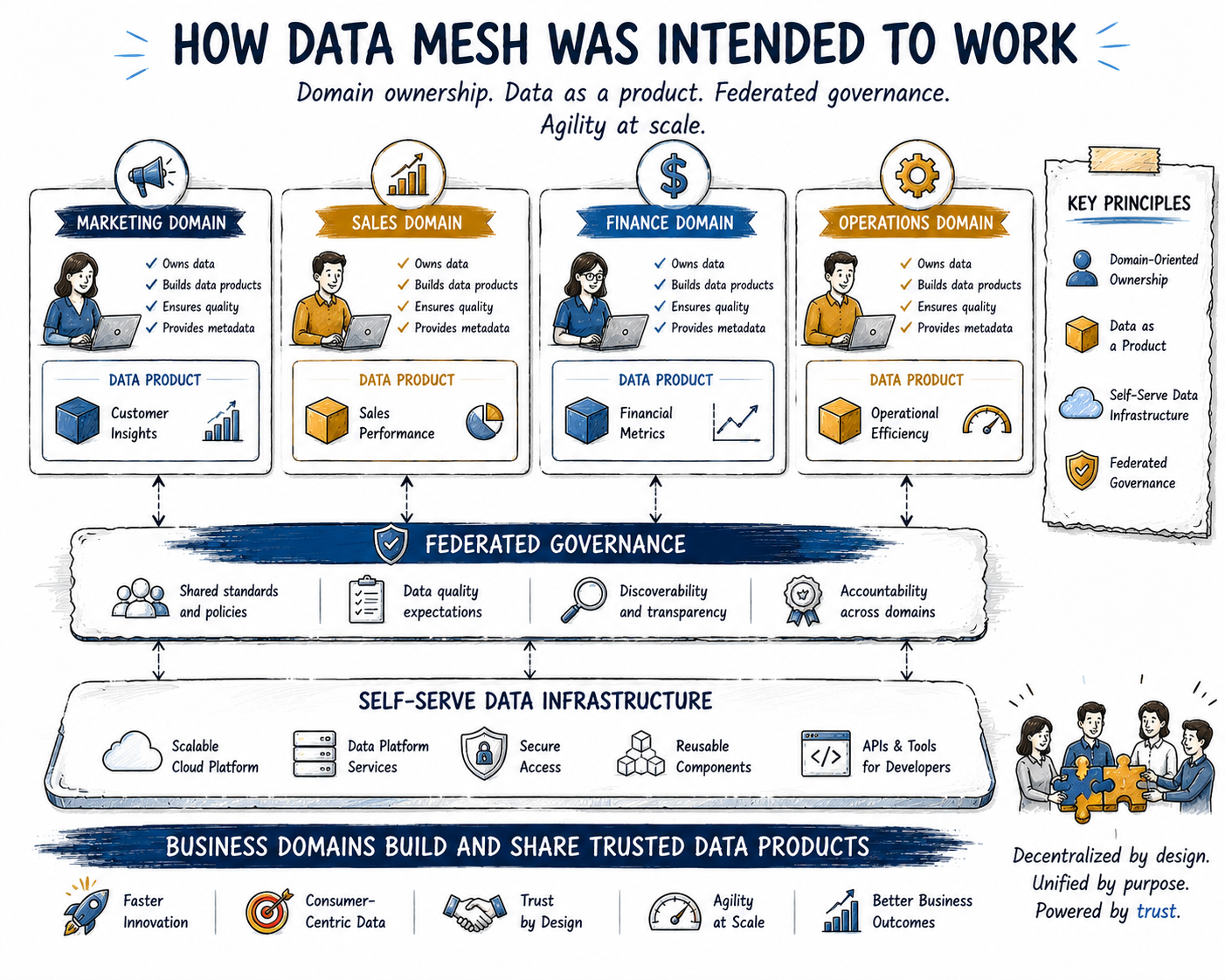
The Governance Challenge
However, autonomy doesn't mean anarchy. Some level of governance and contract between producers and consumers is needed to ensure trust and interoperability. This is where data contracts enter the conversation, but their role is controversial. Do they support the data mesh vision of domain empowerment, or do they inadvertently recreate the bureaucracy that data mesh intended to escape? To answer this, I first define what data contracts are and examine their promised value.
What Are Data Contracts?
(A Kin to Software Interface Contracts)
A data contract is essentially a formal agreement or specification of what a data product will deliver to consumers. In practice, it defines the schema, structure, allowed values, and sometimes non-functional aspects (like freshness or availability SLAs) of data shared between a producer and consumers. In other words, it's a documented guarantee: 'a definition of what you can expect from a data product'. Much like an API contract in software, a data contract serves as a single source of truth about the data exchange, providing clear rules and expectations for both sides. For example, a contract might specify that a "CustomerOrders" data product will have fields OrderID (integer), OrderDate (date, not null), etc., and that data will be updated daily by 6am, with certain quality thresholds.
The rationale is that by aligning producers and consumers upfront, we can prevent surprises. The producer won't accidentally change a column type or drop a field without notice, and the consumer can build use cases with confidence in the data's consistency. Data contracts often include:
Schema and semantics
The structure and meaning of the data (attributes, data types, constraints).
Data quality metrics
E.g. completeness, uniqueness, valid value ranges, etc., that the data will adhere to for trustworthiness.
SLAs
Service-level agreements on data availability or freshness (e.g. data latency, update frequency).
Ownership and change management
Who owns the data product, who to contact, how changes will be communicated or versioned.
In essence, a data contract for a data product acts like "instructions [for] flat-pack furniture": it lists all the parts and how they fit, assuring the consumer that if something is wrong, it's the product at fault, not the instructions. This clear specification "creates a guarantee of services which, in turn, generates trust in the product".
Analogy to interface contracts
This concept closely mirrors interface contracts in traditional software engineering. In the past, technologies like CORBA and enterprise service buses encouraged defining rigid interface specifications between systems. The intent was to standardize interactions and provide stability. However, history offers cautionary tales. Interface contracts, while improving consistency, often introduced inflexibility that hindered progress. A retrospective look shows that many Enterprise Application Integration projects in the early 2000s failed. Gartner reported 70% of such projects failed, largely due to management and adaptability issues, and "the rigidity of interface contracts contributed to these failures by creating bureaucratic bottlenecks and hindering adaptability". Similarly, CORBA, once a hopeful standard for seamless cross-system communication, gained a reputation for complexity and inflexibility, with its strict interface definitions leading to poor adoption. In other words, interface contracts could become an obstacle rather than an enabler when they couldn't keep up with change.
This parallel is important. Data contracts sound a lot like those interface contracts from the past, rigid agreements meant to enforce consistency. As one data executive noted, "data contracts…promise better data quality and reliability, but history shows that rigid contracts often stifle innovation and create workarounds rather than solutions". The data industry must ask: Will data contracts revolutionize data management, or are we repeating old mistakes?
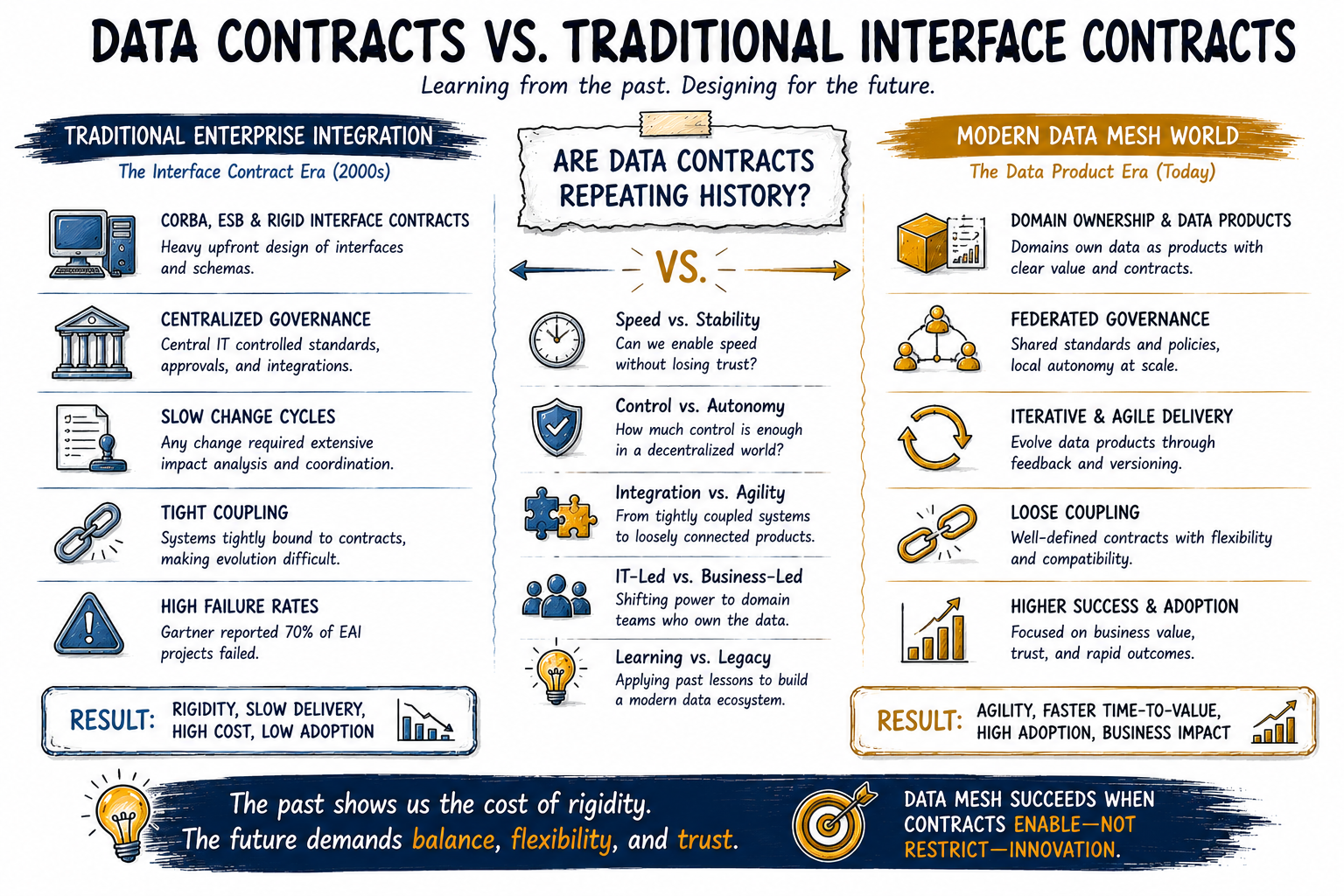
To answer that, let's weigh the promised benefits of data contracts against the potential drawbacks, especially in the context of a data mesh's need for agility.
The Promise: Benefits of Data Contracts in a Data Mesh
Advocates of data contracts argue they are a necessary foundation for trust and reliability in distributed data ecosystems. In a data mesh where many teams produce and consume data independently, things can descend into chaos if changes are uncontrolled. Proponents claim data contracts bring much-needed order and confidence:
Trust and Data Quality
A well-defined contract gives consumers confidence that the data meets certain standards. It's essentially a guarantee. Just as an API contract assures a developer how an API will behave, a data contract assures analysts and data scientists of the schema and quality of a dataset. This builds trust in the data product. By explicitly documenting expectations (valid values, nullability, business rules, etc.), contracts reduce ambiguity. If all teams "trust the data they're leveraging", they can make decisions faster and with greater confidence. The contract acts as the "frontline defense for data quality", catching schema or type mismatches early so that invalid data doesn't propagate. The result is improved data confidence and decision-making based on reliable data.
Stability and Predictability
Data contracts aim to prevent the nightmare of broken use cases or failing processes due to an upstream change. They achieve this by enforcing schema consistency and requiring coordination on changes. For example, if a product team wants to rename a column or change a data format, the contract means they must communicate this change and perhaps version the contract rather than surprise downstream consumers. In effect, the producer ensures they are "not accidentally causing breakages downstream", and the consumer is assured that the data "will not be broken" unexpectedly. This schema enforcement is akin to type-checking in software. It catches incompatible changes early. By formalizing change management, contracts bring predictability to the data's evolution. Teams can "ensure changes are properly communicated and managed" so that downstream systems adapt in sync. The benefit is fewer fire-drills caused by surprise changes and a more stable analytics environment, which is crucial for business stakeholders who rely on consistent metrics.
Schema Enforcement
Catches incompatible changes early through validation.
Change Management
Ensures proper communication and coordination.
Stable Analytics
Consistent metrics for business stakeholders.
Schema Enforcement and Quality Control
A data contract often encodes data quality rules (e.g., no negative values, certain fields must be unique) and can be coupled with validation tests. This enforces that data products not only have the right shape but also sensible content. Data quality issues get caught at the source, shifting responsibility "left" to the producers who generate the data. In traditional setups, a central data team might discover data issues late in the pipeline; with contracts, the domain team (producer) is accountable upfront. This leads to "highly reliable quality checks" maintained by those with the best understanding of the data (the domain). In the long run, it improves overall data hygiene and reduces the burden on centralized quality enforcement. Additionally, having an agreed schema and semantics fosters compliance with regulations (e.g., ensuring PII fields are properly flagged or not exposed if not allowed), an important point for governed domains like finance or healthcare.
Clear Communication and Accountability
By explicitly documenting what a data product contains and what SLAs it meets, data contracts formalize the relationship between producers and consumers. This clarity prevents miscommunication. Producers know exactly what obligations they have (for example, "I must provide data by 8 AM daily, and include fields X, Y, Z with these meanings"), and consumers know the contract terms they can rely on. It sets the expectation that if something changes, it won't be done in the dark. This can create a healthier collaboration culture: instead of ad-hoc, tribal knowledge about data, there is a shared contract everyone references. Some experts note that contracts "foster a feedback culture between data producers and consumers, turning a chaotic environment into a collaborative one". Essentially, the contract is a communication tool as much as a technical one. It gets teams talking about data as a product with defined interfaces and responsibilities. For business stakeholders, this clarity and assignment of responsibility (data issues go to the owning domain to fix) increases trust that data ownership is handled professionally.
Better Change Management and Scaling
As organizations grow their data landscape, keeping track of schemas and changes informally becomes unsustainable. Data contracts introduce version control to data schemas. When evolution is needed (say adding a new column or deprecating an old one), the contract approach encourages a controlled rollout, e.g., introduce a new contract version, notify consumers, perhaps support both old and new for a deprecation period. This disciplined approach to change is directly borrowed from software versioning and prevents the "move fast and break things" mentality from breaking critical analytics. Over time, such practices can "scale a distributed data architecture effectively" by providing structure amid the distributed chaos. Also, debugging becomes easier when contracts are in place. If a pipeline breaks, engineers can compare data against the contract to pinpoint what violated the expectations. For the enterprise, this means less downtime and quicker issue resolution, which is a business value (more reliable reports, less time firefighting).
In summary, the case for data contracts is that they bring the rigor of software engineering to data. They promise trust, stability, quality, and clarity, which are all vital in a federated data mesh. Done well, they can align with data mesh's goal of "trustworthy, discoverable data products" by ensuring each product meets a known standard. It's easy to see the appeal: many organizations struggling with unreliable data pipelines see contracts as a solution to tame the unpredictability. Data contracts, proponents argue, are the key to building reliable data products that consumers can depend on, thereby accelerating (not hindering) the adoption of data mesh. However, these benefits come with assumptions and trade-offs. The very things that make contracts useful (predefined schemas, controlled change), can become liabilities in a dynamic environment. Next, I examine the other side of the debate: how data contracts might impede the agility and innovation that data mesh seeks to unleash.
Do Data Contracts Impose Dangerous Rigidity?
While data contracts offer an appealing promise of order, critics point out that rigid agreements can backfire in a fast-moving, domain-driven system. The phrase 'flexibility vs. stability' captures the heart of this debate. Just as overly strict interface contracts in software led to slow progress, strict data contracts can become a bottleneck in a data mesh. Let's break down the key concerns:
Reduced Agility and Slower Time-to-Market
Data mesh is meant to enable domains to iterate quickly on their data products in response to changing business needs. In reality, "business requirements frequently change and often require agility and velocity". New data use cases emerge rapidly (especially with today's AI and analytics advancements), and domain teams need freedom to adjust their data outputs. Data contracts assume producers and consumers can align upfront on schemas and expectations – but this is rarely practical in a volatile environment. If every change to a dataset's schema or structure requires renegotiating the contract and getting buy-in from all consumers, the pace of innovation slows dramatically. What should be a quick tweak or addition could get held up in a review process. As one commentary noted, "with strict contracts, every modification requires negotiation and coordination, slowing down data product creation and utilization". Instead of empowering teams to iterate, contracts can create bureaucratic bottlenecks that delay new features or data improvements. This delay is essentially a slower time-to-market for data consumers, those waiting on new data or changes might have to sit through committee approvals or version cycles. The very competitive advantage of a data mesh (speed and adaptability) can be undermined if contracts make every change heavy. In short, rigidity stifles agility: a data product team that's handcuffed by an inflexible contract cannot rapidly experiment or pivot to deliver value.
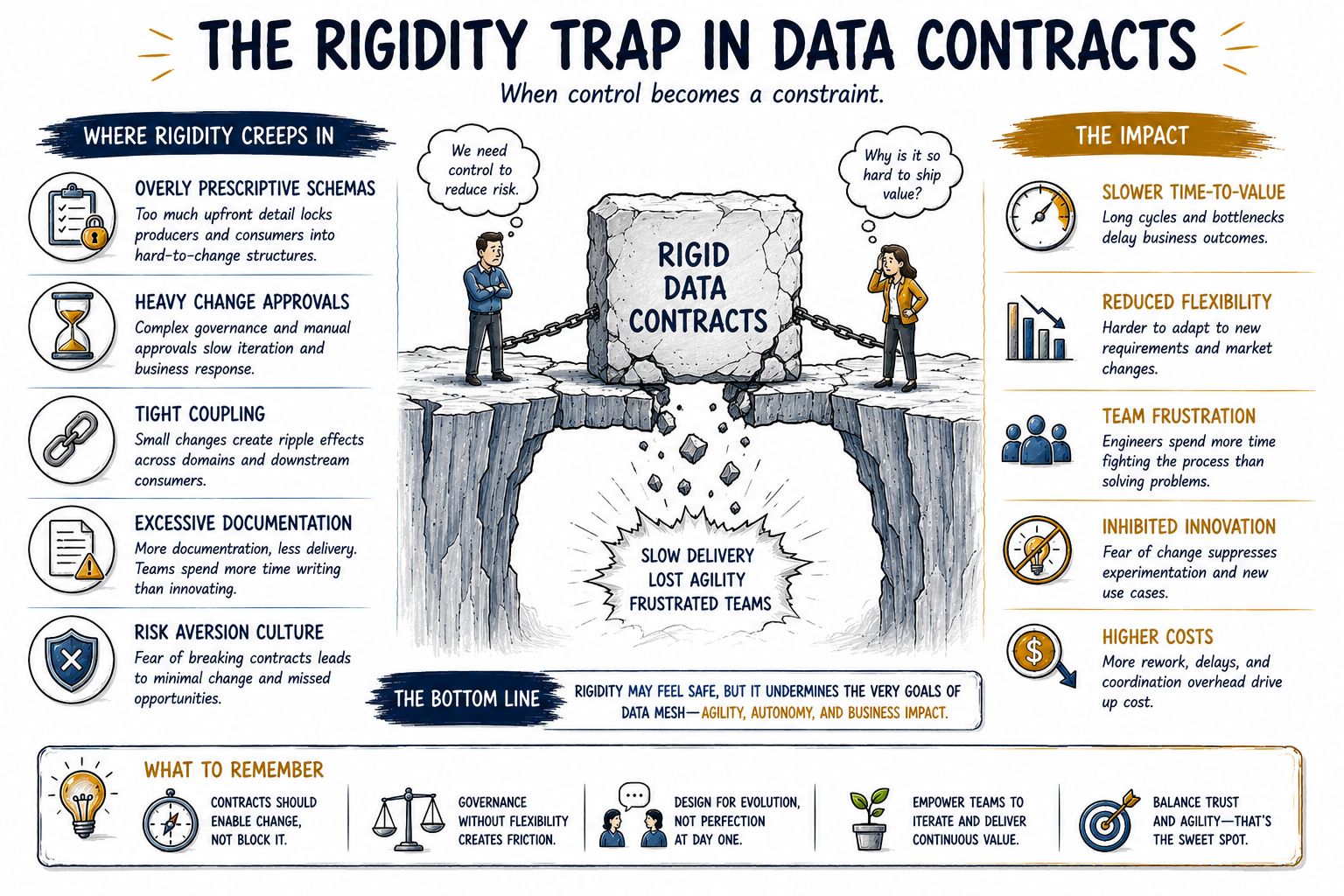
Innovation Needed
Business requirements change rapidly.
Contract Negotiation
Every change requires coordination.
Delayed Delivery
Slower time-to-market for consumers.
Innovation vs. Standardization
Innovation often involves trial and error, iterating on datasets, adding new signals, or reinterpreting data in novel ways. If data producers must strictly adhere to a contract, they might be reluctant to experiment with their own data product for fear of breaking the contract. The contract becomes a conservative force. To take an analogy in software, imagine if every time a developer wanted to refactor internal code, they needed approval from all API clients, it would freeze internal innovation. Similarly, in data, a contract "locks in" certain structures that might have been designed with initial knowledge. As needs evolve, that initial design could prove suboptimal, but changing it is hard. This can lead to a phenomenon where teams "design by contract" focusing on appeasing current consumers, rather than trying new ideas with the data that might benefit consumers in ways they haven't anticipated. The time and effort to update a contract (documentation, versioning, communication) might discourage teams from making beneficial changes, effectively ossifying data products. In a domain-autonomous model, this feels counterintuitive, domains were supposed to have freedom to optimize their data. Overly strict contracts thus impose a static worldview in a dynamic domain, potentially causing the system to miss out on innovative uses of data that don't fit the current contract.
Workarounds and Shadow Data Pipelines
Warning: Paradoxically, imposing strict controls can encourage the very chaos they intend to prevent. If data consumers find the official data products too slow to change or too constrained, they may seek alternate paths to get the data they need.
This is a familiar pattern in organizations, when IT processes are too slow, business units create "shadow IT" workarounds. Likewise, with data, if a contract "blocks a critical use case, users will find other ways to get the data", warns one expert. For example, if a needed field isn't in the contract, an analyst might directly query the source database or scrape an application for the data, bypassing the governed data product. If a contract delay is holding up a fix or a new data feed, teams might spin up unofficial pipelines to meet their deadlines. These workarounds undermine the single-source-of-truth vision. As the analysis put bluntly, "instead of improving data quality, contracts could drive more fragmentation and less governance, the exact opposite of their intent". In a data mesh, the last thing we want is each domain or department doing their own hidden data integrations because the sanctioned route is too cumbersome. Such shadow data flows reintroduce siloed, inconsistent data, eroding trust and governance. This counterargument suggests that overly rigid contracts might push organizations back toward the "data swamp" that mesh hoped to escape, as frustrated consumers take data matters into their own hands.
Contracts ≠ Cure-All for Data Quality
A key selling point of data contracts is improved data quality. But skeptics note that "data quality is an ongoing process, not a one-time agreement". Having a contract on paper doesn't automatically ensure the data will be perfect; it must be enforced and maintained continuously. If a data contract is treated as a silver bullet, teams might become complacent, thinking the contract itself guarantees quality, when in reality data can drift or degrade due to factors outside the contract's scope (like upstream source issues). Quality requires active monitoring (data observability), tests, and frequent communication, none of which are magically solved by writing a contract. In fact, if too much emphasis is put on upfront contract stipulations, teams might under-invest in real-time monitoring and validation. Modern data reliability approaches favor automated monitoring of data freshness, volumes, anomalies, etc., to catch issues as they happen. Contracts typically don't prevent issues; they just specify them. Without enforcement and observability, a contract could give a false sense of security. "Contracts alone don't solve the real issue," one industry blog notes, "data quality isn't about strict rules; it's about trust, monitoring, and adaptability.". In other words, you can't just "sign and forget" a data contract, it requires the same diligence as any data governance process. If organizations focus on contracts over building robust quality processes, they may be disappointed. A data mesh thrives on continuous data product improvement; quality must be continuously evaluated, not assumed true because it's in a contract.
Increased Governance Overhead and Complexity
Implementing data contracts is not a trivial task. It introduces another layer of governance that teams must learn and manage. Each contract must be written, agreed upon, versioned, and enforced (often via tools or pipeline checks). For organizations already struggling with data governance, this can be a steep hill to climb. It demands that domain teams have advanced data engineering maturity. They need to understand schema design, backward compatibility, and possibly use tooling to validate contracts in CI/CD pipelines. Not all teams have that skillset readily. As noted in one discussion, "implementing data contracts demands a deep understanding of both the data and its applications. Without proper expertise, organizations may face integration issues, leading to project delays or failures.". This means that in trying to introduce contracts, some early data mesh adopters have hit technical roadblocks or slowdowns, simply because it adds complexity to an already complex transformation. Culturally, there can also be resistance. Decentralizing data ownership is a big shift, and asking domain teams to also take on writing formal contracts might be overwhelming. If teams push back or fail to adopt the practice, the whole system could stall. In essence, heavy bureaucratic processes can discourage domain teams from truly taking ownership. Data mesh is supposed to enable domain teams, not burden them with paperwork and process. As one whitepaper succinctly puts it, "robust governance does not stifle innovation; it enhances data reliability and builds trust" - but the governance mechanisms must be balanced and not overbearing. If every data change feels like a bureaucratic exercise, domain teams might disengage, and stakeholders might find the mesh initiative too slow or complicated to deliver value.
The Interface Contract Analogy: Learning from History
The concerns above echo the lessons from traditional software mentioned earlier. It's worth underscoring this parallel. In software engineering, rigid interface contracts often had to be softened with more agile practices. For instance, APIs evolved to include versioning and deprecation strategies so that services could change without breaking consumers overnight. Agile development methods embraced iterative development over big upfront designs. Data contracts, if treated like inflexible interface agreements, could fall into the same trap as CORBA or large EAI frameworks did, technically sound in principle, but failing against the reality of constant change. There is a risk that organizations enthusiastically adopt data contracts everywhere ("every data pipeline must have a contract and cannot change without approval"), only to find a year later that their data innovation has ground to a halt under process overload. In the worst case, we risk re-centralizing control through contracts, as a strict contract policy can start to resemble the old centralized gatekeeper model ("You can't publish that data until the contract committee signs off"). This directly conflicts with data mesh's federated governance ideal, where governance is meant to be lightweight and enabling, not a choke point.
In summary, the critique of data contracts in a data mesh is that they trade agility for assurance, and if taken too far, that trade can hurt more than help. A data mesh is a living ecosystem, it needs to evolve rapidly with business needs. Hardline contracts could become like concrete on the feet of domain teams, slowing every step. Additionally, human nature finds ways around roadblocks; too much rigidity and people will route around the "official" pipelines, undermining the very trust and order we tried to create. Does that mean data contracts are bad outright? Not necessarily. It means we must strike the right balance. Let's consider the counterarguments more formally and how to reconcile these viewpoints.
Counterarguments and Rebuttals: Weighing Trust vs. Agility
It's important to acknowledge the valid points on both sides of the debate. Below, I present key arguments in favor of data contracts (why many teams advocate for them) and provide rebuttals from the agile data mesh perspective.
Key Debates
“We need trust, consistency, and schema stability. Data contracts provide a safety net.”
Data consumers have long suffered from broken pipelines or unexpected changes. Having a contract means they can trust that data won't change out from under them. This stability is crucial for things like quarterly reporting or ML models in production. You can't retrain a model overnight because someone changed the data schema unexpectedly. The contract is akin to a legal agreement of the data's fidelity and schema, which builds trust and allows more people to confidently use the data. Business leaders also like the idea of guaranteed SLAs for data (e.g., the sales dashboard data will be updated by 9am daily with yesterday's complete orders dataset). That reliability is non-negotiable in many enterprises.
Stability can be achieved without sacrificing adaptability. Techniques like schema evolution and versioning can allow changes to happen in a controlled way without breaking consumers. A domain team can introduce changes behind a new version of their data product, and gradually migrate consumers (much like APIs versioning). Robust data observability can alert consumers to changes or issues in real-time. It's possible to maintain trust by being responsive and transparent, rather than by never changing anything. An overly rigid contract might give a false sense of consistency – things appear stable but needed changes get postponed, accumulating technical debt. An adaptable contract or clear versioning policy can provide stability and agility.
“Data contracts enforce data quality and accountability at the source.”
By making domain teams explicitly state and validate the quality of their data, organizations shift the responsibility to where it belongs, the source. This 'quality at the source' approach is highly effective; it's better to prevent bad data from ever entering the pipeline than to fix it downstream. Data contracts formalize this by, for example, not allowing a producer to publish data that doesn't meet the agreed constraints. It also clarifies who is accountable: if the contract is violated, the producing team must fix it. In domains with compliance requirements (think GDPR, HIPAA), contracts can ensure all needed safeguards are documented and met.
Quality can't be assured by contract alone. It requires continuous processes and a culture of collaboration. A rigid contract can become a blunt instrument. If data drifts due to external factors, strictly enforcing the old contract could actually block the data pipeline, which might be worse than passing the slightly 'imperfect' new data with a warning. A more agile approach to quality is to monitor and inform. Let the data flow but flag anomalies and involve humans in the loop when needed. As one expert noted, 'data quality isn't about strict rules; it's about trust, monitoring, and adaptability.'
“Without contracts, it's a free-for-all. Contracts provide governance and prevent chaos.”
A major fear in decentralized data environments is loss of control. Data contracts are seen as a governance mechanism to keep chaos at bay. They standardize how data is shared across the organization, much like how API standards brought discipline to software integrations. Every contract can include owner info, data classification, etc. They formalize governance in a decentralized but coordinated way and 'bring structure and traceability, helping to scale data practices sustainably.'
Governance is crucial, but it must be lightweight and adaptive in a data mesh. The question is how to achieve governance without heavy-handed rigidity. Governance can be implemented via automation and policy-as-code rather than manual contract negotiations. Automated schema checks can block only truly breaking changes and allow non-breaking changes through with notifications. As Zhamak Dehghani reminds us: 'The key to data success isn't rigidity; it's flexibility combined with strong governance.'
“Our industry is regulated/high-stakes – we can't afford errors or spontaneous changes.”
Certain domains (finance, healthcare, aerospace, etc.) have very low tolerance for data issues. A single schema error or unexpected data change could violate laws or cause serious business damage. Data Tiles notes that contracts can be useful in regulated environments: 'in finance, healthcare, and compliance-heavy industries, contracts help enforce rules on data privacy, accuracy, and security.' If a particular data product is mission-critical, having an explicit contract with an uptime SLA and quality guarantees makes sense to the business.
This is a point of agreement. Data contracts do make sense in high-risk, regulated scenarios, but that doesn't mean they should be everywhere. Apply contracts selectively. Use them as a scalpel, not a hammer. The data mesh should allow different governance levels for different datasets based on criticality. The ideal solution is a tiered approach: identify which data products truly need the formal contract treatment and which can be managed with lighter processes. Use contracts where the trust gained outweighs the speed lost, and favor more agile mechanisms elsewhere.
“Interface contracts worked for software APIs; we should do the same for data – it's just good engineering.”
Modern software development heavily relies on API contracts (OpenAPI/Swagger, gRPC schemas, etc.) and it's considered a best practice to define and stick to those interfaces. It has enabled microservices to communicate reliably at scale. By introducing data contracts, we apply decades of software lessons to make data integration more robust. A well-designed contract doesn't preclude agility; it just provides a stable interface for agility to happen behind it. Engineers can change their internal implementations as long as they honor the contract.
The software analogy is useful, but not absolute. Data is often used in a more exploratory way than services. Consumers might combine and repurpose it in ways producers never imagined. Overly strict contracts could limit serendipitous use of data. In data, dependencies can be more opaque, and breaking changes can spread widely. Adopt the spirit of API contracts (clear interfaces) but cautions against the letter (excessive rigidity). As Deloitte put it, 'true data agility comes from balancing structure with adaptability, not enforcing rigidity.'
Finding the Balance: Flexible Contracts and Data Mesh Harmony
Both the proponents and opponents of data contracts make compelling points. How can organizations reconcile these to get the best of both worlds? The answer likely lies in balance and context. A nuanced approach can ensure that governance does not suffocate innovation. Here are some guiding principles and emerging best practices:
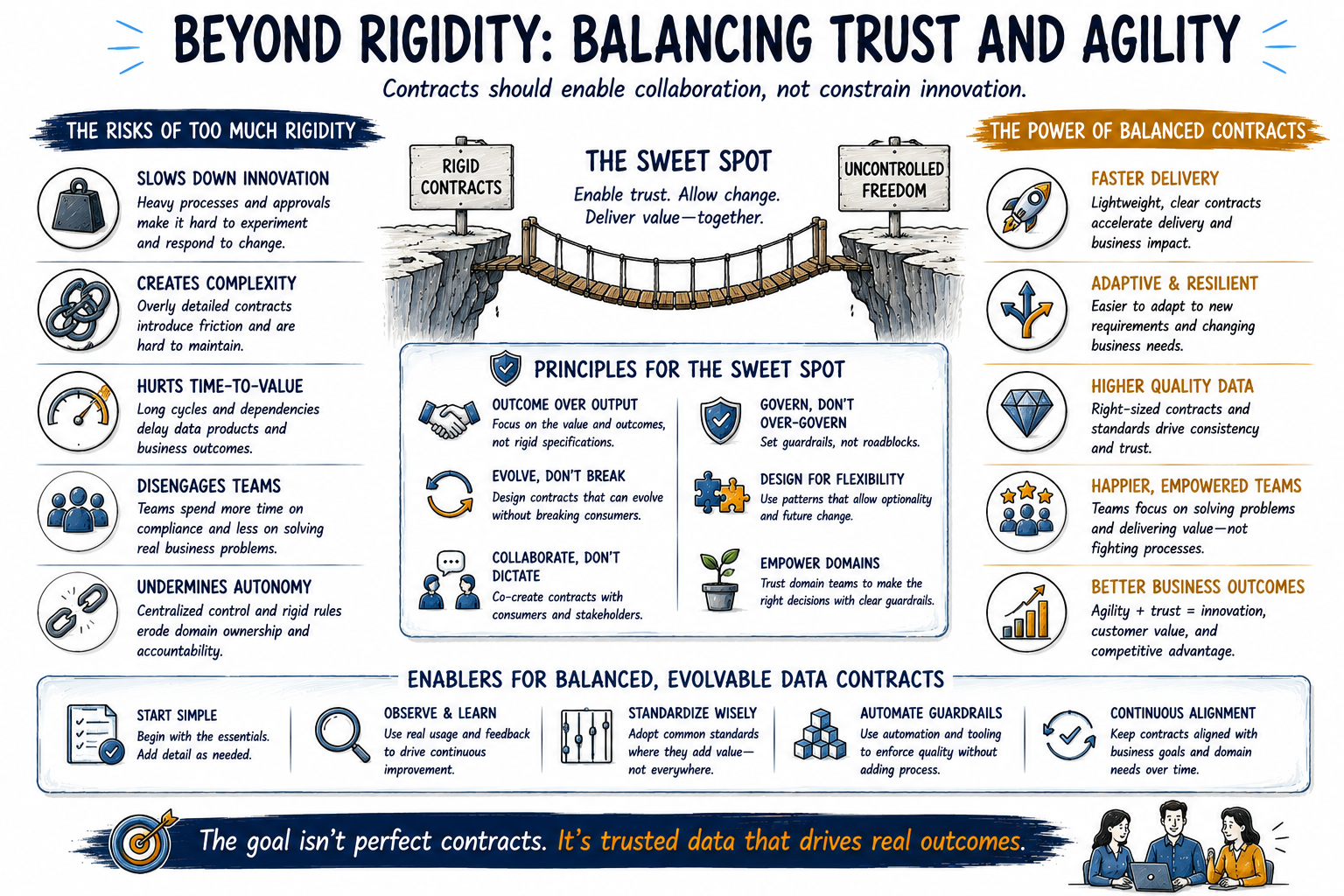
Use Data Contracts Selectively and Thoughtfully
Not every data set or data asset requires an elaborate contract. Identify the critical data products, those where errors or sudden changes would be catastrophic (financial reports, regulatory data feeds, key executive dashboards), and apply stricter contracts there. For more experimental or rapidly evolving data products, use lighter-weight agreements (or at least faster-moving contracts) to allow quick iteration. It's perfectly fine to have different tiers of contracts within the same data mesh. Domain teams should assess their data product's consumers and SLAs to decide the level of formality needed. As one blog advised, avoid 'over-complex contracts' and keep them as simple as possible while meeting requirements.
Embrace Schema Evolution and Versioning
A contract doesn't have to mean 'no change.' Borrowing a page from agile APIs, implement a clear versioning strategy for data contracts. Producers can introduce a new version of the data product with changes, and consumers can migrate at their own pace. Tools should allow multiple versions to run in parallel during a transition. Also, consider 'soft deprecation' strategies: mark fields or features as deprecated in the contract before removing them. Schema registries and contract testing frameworks can automate checking compatibility of new versions. Contracts become living documents that can grow, rather than static ones that shatter when touched.
Invest in Data Observability and Communication Channels
Instead of relying solely on contracts to catch issues, implement data observability tools that monitor data freshness, completeness, and anomalies continuously. Foster a culture (and provide platforms) where producers and consumers can easily communicate about changes — a shared Slack channel or a subscriber notification system. The goal is to maintain trust through openness and quick response, not just through rigid rules.
Automate Contract Enforcement in CI/CD
Use automation to enforce what contracts you do have. Integrate a test in the data pipeline deployment that fails if the schema changes in a non-allowed way. Configure these tests to still permit agile practices: allow additions of new fields automatically, while truly breaking changes (like deletions or type changes) are flagged for review. Notification of contract violations can precede hard enforcement. The enforcement is technical, not bureaucratic.
Leverage Domain Knowledge and Consumer Feedback
Domain teams should regularly engage with their consumers (perhaps via product management practices for data). Treat the contract as a living reflection of a conversation between producer and consumers. Keeping that conversation active is key to balancing rigidity and flexibility. Focus on the relationship, not just the contract artifact. Treat consumers as customers.
Consider Alternative Patterns
Some organizations explore alternatives or complements to data contracts. BITOL — 'Build It, Test Once, Leverage' — emphasizes test-driven data pipelines and continuous validation over static contracts. Consumer-driven contracts (inspired by contract testing in microservices) flip the model: consumers define what they expect, and producers ensure they meet those expectations. Data catalogs and metadata platforms also provide a way to share schemas and context without formal handshakes every time.
Ultimately, the goal is to uphold the principles of data mesh – domain autonomy, decentralization, and fast delivery of value, while still ensuring trust and reliability. The consensus among forward-looking experts is that this requires a flexible approach. A quote attributed to a Deloitte 2023 data report encapsulates it: "True data agility comes from balancing structure with adaptability, not enforcing rigidity." And an IBM insight similarly notes that good governance is knowing when to be flexible versus when to enforce. The founder of data mesh, Zhamak Dehghani, also cautions against strictness: "The key to data success isn't rigidity; it's flexibility combined with strong governance."
All these voices align on a clear message: find the middle ground.
Join a Data Conversation,
Cameron Price

Cameron Price is the Founder and CEO of Data Tiles and creator of Latttice, the AI-powered Data Product Workbench designed to enable business-built, trusted, governed data products that drive better decisions. With decades of experience across enterprise data, analytics, cloud, and organizational transformation, including leadership roles across consulting and global technology organizations, Cameron has worked with enterprises to solve complex data access, governance, and operational data challenges. His work focuses on practical approaches to Data Products, Data Mesh, AI readiness, and Active Governance, with a strong belief that trusted, governed data products should be accessible at the point where business decisions are made.
References
- Zhamak Dehghani, Data Mesh: Delivering Data-Driven Value at Scale, O'Reilly Media, 2022.
- Gartner Research — Research and commentary on enterprise integration, data governance, distributed data architectures, and data management trends.
- Deloitte Insights — Research and industry commentary on balancing governance, agility, and AI-ready data strategies.
- IBM Data Governance Insights — Guidance on modern governance, data trust, observability, and enterprise data quality practices.
- Thoughtworks Technology Radar — Commentary on data mesh adoption, decentralized architectures, and modern engineering practices.
- Martin Fowler – Consumer Driven Contracts.
- Confluent Schema Registry Documentation — Schema evolution, compatibility management, and distributed data contract approaches.
- OpenAPI Specification — Modern software interface contract and API governance principles.
- Data Mesh Learning Community — Data mesh implementation patterns, governance approaches, and domain-oriented data product practices.
- McKinsey Digital Insights — Enterprise AI transformation and data modernization research.
- Forrester Research — Research covering AI readiness, governance maturity, and modern data operating models.
- IDC Research — Commentary on distributed data ecosystems, AI operationalization, and enterprise data adoption trends.
- CORBA Overview – Object Management Group.
- Cameron Price, Founder and CEO of Data Tiles — Practitioner insights and operational experience across enterprise data, analytics, cloud, governance, Data Products, and AI-powered data access transformation.
- Data Tiles — Research, white papers, and commentary on Active Governance, Data Products, and AI-powered business data access.
- Latttice — The AI-powered Data Product Workbench designed to enable business-built, trusted, governed data products for better decisions.